
Det største og mest ambisiøse løftet var å migrere fra én monolittisk database til 55 shards – noe utviklingsteamet har klart uten nedetid. Nesten.
Snakker du ikke “utviklersk”? Underveis i artikkelen har vi lagt inn noen forklaringer og oversettelser, som forhåpentligvis gjør det litt enklere for deg å henge med i svingene.
Når én database ikke lenger holder
Tripletex startet i 2002 som en fullverdig SaaS-løsning. I dag kjører den som en Java-monolitt med Java 21 og Spring 6, i AWS (Amazon Web Services), MySQL Aurora-databaser (en kraftig databaseløsning tilpasset skyen). Med 135 personer i utviklingsavdelingen og deployment av java-monolitten (oppdateringer av systemet) flere titalls ganger daglig, har selskapet bygget et robust system – men veksten i kundemassen og størrelsen på databasen skapte flere utfordringer.
– Vi oppdaget det klassiske problemet: Enkelte databasetabeller helt sentrale i systemet hadde INT som ID-felt, og vi hadde kalkulert at vi hadde noen måneder frem i tid hvor den var forventet å gjøre overflow. Etter det hadde Tripletex i praksis ikke fungert, forteller Harald Kleppe, Development Manager i Tripletex.
Hva betyr dette i praksis? Tenk deg at hver kunde, hver faktura og hver transaksjon i Tripletex får et unikt løpenummer. Problemet var at systemet nærmet seg det høyeste nummeret det kunne håndtere – omtrent som en kilometerteller som er i ferd med å gå rundt. Når den når maksgrensen, stopper systemet å fungere.
En tradisjonell migrering for å fikse dette problemet ville krevd 60 timer nedetid for alle kunder, da både ID-en og alle fremmednøkler måtte endres.
– For en tjeneste som håndterer regnskapet til flere enn 150.000 norske bedrifter, hadde nok ikke det vært så veldig populært, konstaterer Kleppe.
Prøvde tradisjonelle løsninger først
Før teamet kastet seg ut i sharding, prøvde de alle de tradisjonelle triksene: mer CPU, lesenoder, global cache, audit-log-arkivering, optimalisering av domenelogikk, nytt eventsystem. Og så enda mer CPU.
På godt norsk betyr dette: Før de kastet seg ut i den store omleggingen, prøvde de: Mer datakraft, flere kopier av databasen for å fordele trafikken, bedre mellomlagring av data, arkivering av gammel informasjon, og optimaliseringer av hvordan systemet jobber.

– Men skaleringsutfordringene fortsatte, og Tripletex hadde og har fortsatt ambisjoner om betydelig vekst. Så her var det bare én ting å gjøre, og det var å dele databasen, sier Harald.
De vurderte også ferdigløsninger som Vitess og AWS RDS Proxy for å legge et lag mellom applikasjonen og databasen.
– Tanken var at samme applikasjon skulle tro den snakket med mange databaser. Men ingen fungerte. Enten manglet de Aurora-støtte, eller de introduserte altfor mye latency (gjorde systemet for tregt). Så da var det ikke noe annet å gjøre enn å bygge dette inn i rammeverket.
Nysgjerrig på Tripletex? Sjekk ut våre ledige stillinger
Enkle løsninger på komplekse problemer
Med hele utviklingsavdelingen involvert måtte teamet først definere målene: ytelse for hver kunde, raske migreringer uten fancy verktøy, og skalerbarhet. Men hvor mange databaser trengtes?
– Vi skulle ha mange nok databaser til at det skalerte. Men betyr det 30 eller 300? Det var det ikke noe fasit på, sier Harald.
Løsningen ble cirka 40-50 shards (databaser) spredt over tre til fem clustre. Det naturlige valget for sharding-nøkkel var company-ID-kolonnen, som finnes i alle databasetabeller med kundedata.
Sharding betyr ganske enkelt at man deler opp dataene. Istedenfor at alle kundenes data ligger i én stor database, legger man ulike kunder i forskjellige databaser. Det blir som å gå fra ett stort lager til flere mindre, så det både blir lettere å finne frem og køen blir kortere.
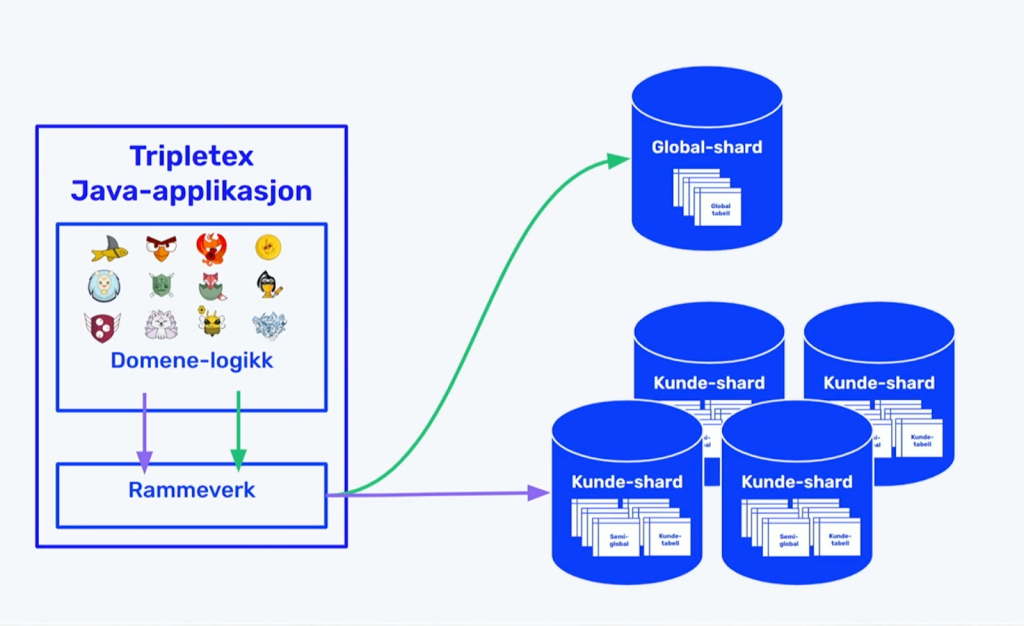
I Java-koden ser en vanlig modell ut som før, uten anoteringer – standarden er kundespesifikke data. Globale modeller (data som gjelder alle) får en global-annotering som forteller rammeverket hvordan de skal håndteres. I tillegg har de semiglobale modeller, som rapportmodellen, hvor kunder kan bruke både systemverdier og opprette egne verdier.
For overgangsfasen utviklet de funksjonalitet for å finne objekter uavhengig av hvilken database de ligger i – såkalt “scatter-gather”.
– Det var helt nødvendig for å komme fra én til mange databaser. Men også en hemsko – å spørre mange databaser for å finne ett objekt er verken effektivt eller gir god ytelse, forklarer Harald.
I stedet for oppslag på hver forespørsel om hvilken database en kunde ligger i, laster de informasjonen ved oppstart.
– Det fungerer fint fordi vi deployer (oppdaterer systemet) mange ganger om dagen. Informasjonen er gyldig så lenge applikasjonsserveren kjører, sier Harald.
Les mer om Tripletex og se deres team, roller og utviklingsprinsipper.
Fire faser uten “big bang”
– Vi pleier ofte å hoppe i det med “build, measure, learn” som sentralt i metodikken. Men her var det en stor jobb som gikk over flere år, og vi måtte bruke litt tid på å se på alternativene først, forklarer Harald.
Sharding-prosessen ble delt inn i fire faser uten store, risikable oppdateringer på én gang:
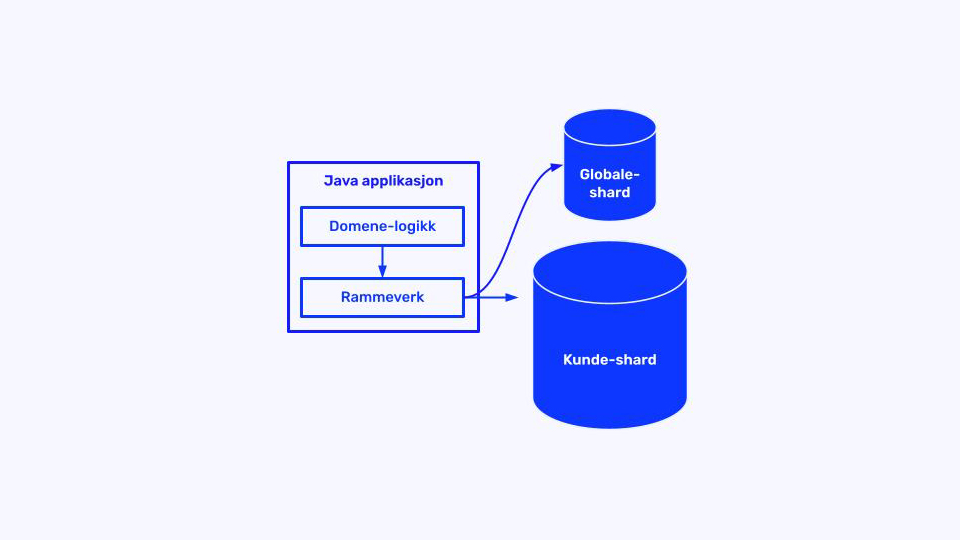
- Grunnlaget: Rammeverksstøtte for å snakke med flere databaser og få all domenelogikk over på å bruke denne. Resultatet? Fortsatt én applikasjon og én database

- Globale data: Flyttet globale tabeller til eget cluster, tabell for tabell. Noen statiske tabeller kunne deployes normalt, andre krevde kort nedetid midt på natta.
– Dette ga dramatisk bedre ytelse fordi masse trafikk ble flyttet ut av det store clusteret, sier Harald.
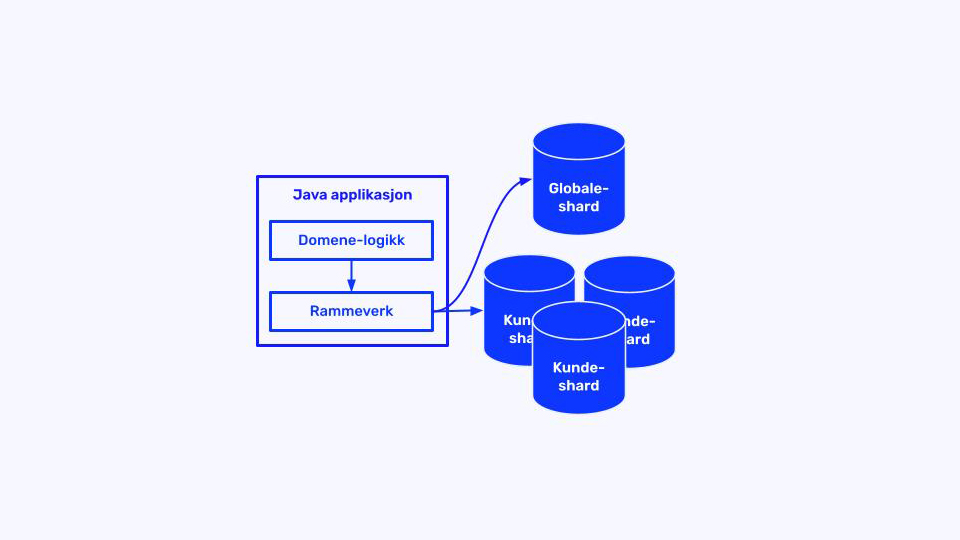
- Ruting: Nye kunder havnet i nye clustre, mens eksisterende gradvis ble flyttet med egenutviklet verktøy. Den jevne strømmen av nye selskaper ga pusterom i den gamle databasen.
– Vi flyttet alle ut fra den gamle til tre nye databaser. Tre var ikke målet, men ga verdifull erfaring med både flytting og forvaltning av mange databaser.
- Sharding nirvana: Oppskalering til mange databaser. Her lærte teamet at 55 shards i tre clustre er “litt annerledes” enn tre databaser.
– Det var mange knapper å skru på – både i databasen og applikasjonen – som vi ikke klarte å forutsi effekten av før de var under produksjonslast.
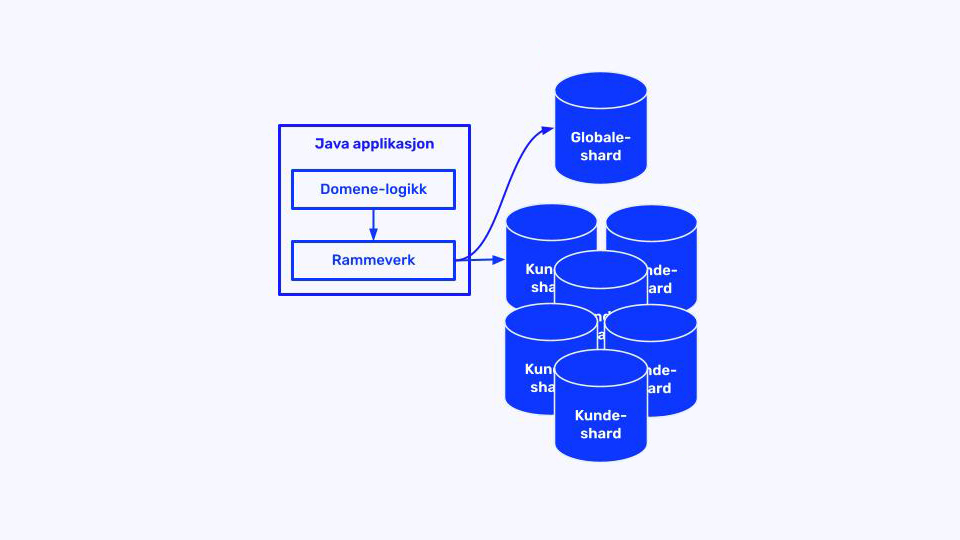
De såkalte scatter-gather-kallene (hvor systemet spør flere databaser samtidig) skapte også problemer: hvis én database var treg, påvirket det alle kunder i altfor stor grad. Dette førte dessverre til noe nedetid i fjor høst, men ga verdifulle lærdommer.
Viktige lærdommer underveis
Fra start var tilnærmingen å søke enkle løsninger på komplekse problemer.
– Det finnes mange potensielle problemer, men du vil ikke klare å forutsi alle. Hvis du beveger deg sakte fordi du bruker masse tid på antatte utfordringer, finner du kanskje ikke det som faktisk vil begrense deg, sier Harald.
Metoden ble i stedet små steg, med høy hastighet og å observere hva som faktisk materialiserer seg som problemer.

– Det er ikke alltid du trenger å fikse alle problemene heller. Ofte holder det å finne rotårsaken og instrumentere det på en måte som gjør at du kan følge godt med for å se om det faktisk blir et problem.
Prosessen ble styrt med et flytskjema for å sikre felles enighet om gjenværende oppgaver og at den til enhver tid viktigste oppgaven ble prioritert.
Status i dag
I dag kjører Tripletex på 55 databaser fordelt på tre grupper med kundedata. 22 av disse er dedikerte databaser for de aller største kundene, som har mye data og får noe igjen av å være i sin egen database.
– Vi hadde mange ‘points of painful return’, men ingen ‘point of no return’, oppsummerer Harald.
Og med en skalerbar løsning på plass er Tripletex klar for videre vekst – uten fare for INT overflow (uten at løpenummeret går rundt og at systemet stopper opp, da altså).
På jakt etter nye muligheter? Sjekk ut ledige stillinger her.





